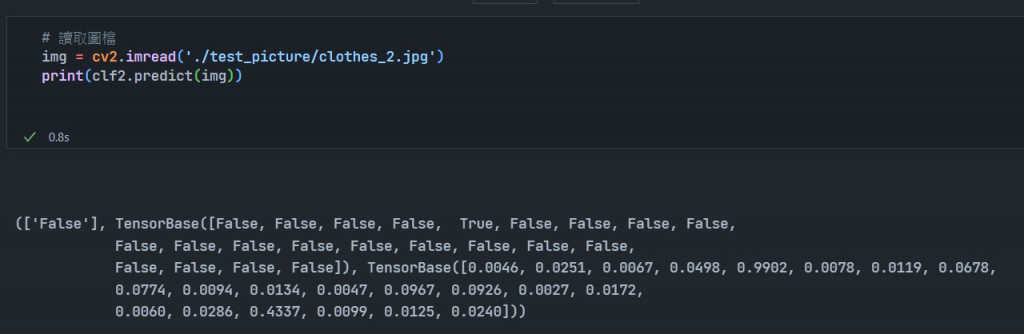
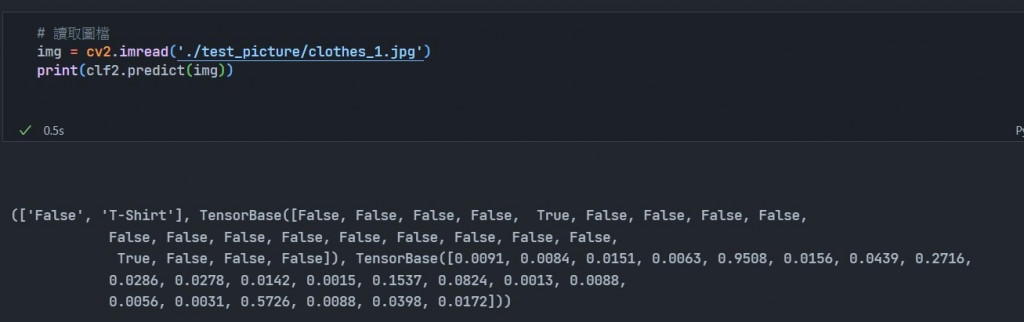
今天終於到了最後一天了,我們之前提過機器學習的演算法,現在我們要說明如何將訓練的model儲存起來,這樣下次要使用時就可以不需要再再重新訓練一次:
要將模組儲存,可以使用sklearn中的joblib:
from sklearn import svm
from sklearn import datasets
from sklearn.externals import joblib
接下來先建立資料集以及預測模型clf:
clf = svm.SVC()
iris = datasets.load_iris()
X,y = iris.data , iris.target
clf.fit(X,y)
要將model儲存只要使用joblib.dump()就可以了:
joblib.dump(clf,'clf.pkl')
前面的clf為我們上面的svm.SVC(),後面的clf.pkl為檔名,這裡我們就稱為clf.pkl。
執行完這段程式碼可以在目錄內看到新增了一個clf.pkl的檔案,現在我們來呼叫它:
clf2 = joblib.load('clf.pkl')
我們就可以直接使用它來做預測了,像這樣:
print(clf2.predict(X[0:1]))
得到結果[0],也就是我們的第一種花。
好了,今天終於走完30天了,首先先感謝自己的努力才能撐過期末考大爆炸,接著要感謝我的團隊隊員們互相打氣?
現在我們就來看看我們這30天做了什麼吧:
所謂工欲善其事必先利其器,一定要先將裝備都準備好:
[Day01]Anaconda環境安裝!
[Day02]Jupyter Notebook操作介紹!
環境已經好了,當然就是練練基本功:
[Day03]Python的基本運算!(上)
[Day04]Python的基本運算!(下)
要使用python做資料分析,一定不能不知道三個重要的程式庫:
用pandas來整理資料吧!
[Day06]Pandas的兩種資料類型!
[Day07]Pandas操作資料的函數!
[Day08]Pandas資料的取得與篩選!
[Day09]Pandas索引的運用!
[Day10]Pandas Groupby使用!
[Day11]Pandas使用多層索引!
[Day12]Pandas處理字串資料!(上)
[Day13]Pandas處理字串資料!(下)
[Day21]Pandas就能輕易將資料視覺化!
用numpy做資料運算吧!
[Day14]Numpy的ndarray!
[Day15]Numpy操作索引&局部資料!
[Day16]Numpy的廣播&方法!
[Day18]Numpy檔案輸入與輸出!
老闆看不懂這些資料啦,直接視覺化給他看!
[Day19]Matplotlib讓資料視覺化!
[Day20]Matplotlib資料視覺化進階!
不喜歡Matplotlib,可以用看看更厲害更簡單的Bokeh
[Day22]Bokeh更簡單的資料視覺化!
沒資料怎麼半?用Beautiful Soup吧!
[Day23]Beautiful Soup網頁解析!
會了資料整理與運算還有視覺化後,我們就可以踏入機器學習這個領域了!
[Day24]什麼是機器學習Machine Learning?
[Day25]機器學習:特徵與標籤!
[Day26]機器學習:KNN分類演算法!
[Day27]機器學習:建立線性迴歸資料與預測!
[Day28]機器學習:特徵標準化!
[Day29]機器學習:交叉驗證!
第一次參加鐵人賽,除了很開心能分享自己所會的,默默的寫技術文章以外,發現自己能夠挑戰完成30天的比賽真的是非常無敵的感動(落淚),而且中間還卡了一個超煩的期末考啊。
所以接下來我也開始挑戰自己的極限!(登冷)也就是不喝飲料30天,除了鍊成鐵人以外還可以身體健康一點點點。
非常感謝大家的訂閱文章給予支持。在此下台一鞠躬!
全部看完了~
謝謝大大的入門教學
覺得Pandas那段看了很有收穫:))
好用心竟然全部看完了!
謝謝你的喜歡與反饋~~~~
感恩唷~棒棒!
全部看完了
寫得很棒,希望有更多作品造福大家
真的感謝各位的支持(鞠躬)我會繼續努力的!
也謝謝各位都有看完還幫我找出錯誤,
太多沒有注意到的小錯誤了不好意思 XD
不好意思請問一下,如果直接呼叫pkl,辨識出來的結果有些奇怪,想看一下標籤的話應該怎麼做?
不知道為什麼有時候可以有結果,有時候出不來